MobileNetV3是该系列的最新版本,该架构在一定程度上是通过自动网络架构搜索(NAS)找到的。
使用MnasNet-A1作为起点,但使用NetAdapt对其进行优化,NetAdapt是一种算法,可自动简化预训练模型,直到达到给定的延迟,同时保持较高的准确性。 除此以外,作者还手工进行了许多改进。
一、V3的改进
本质上,MobileNet版本3是对MnasNet的手工改进。 主要变化是:
(1)重新设计了耗时的层;
(2)使用h-wish而不是ReLU6;
(3)扩展层使用的滤波器数量不同(使用NetAdapt算法获得最佳数量)
(4)瓶颈层输出的通道数量不同(使用NetAdapt算法获得最佳数量)
(5)Squeeze-and-excitation模块(SE)将通道数仅缩减了3或4倍
(6)对于SE模块,不再使用sigmoid,而是采用ReLU6(x + 3) / 6作为近似(就像h-swish那样)
针对第1点,MobileNet v1和v2都从具有32个滤波器的常规3×3卷积层开始,然而实验表明,这是一个相对耗时的层,只要16个滤波器就足够完成对224 x 224特征图的滤波。虽然这样并没有节省很多参数,但确实可以提高速度。
对于第2点,之前V1和V2都是用ReLU6作为激活层,但是在V3中,作者使用了hard swish(h-swish):
\text{h-swish}(x)=x\times \text{ReLU6}(x+3)/6常规的swish使用的是x\times \text{sigmoid}(x),它可以显著提高神经网络的精度,但是sigmoid的计算实在是太耗时了,所以在这里作者使用了ReLU6作为替代。作者认为几乎所有的软件和硬件框架上都可以使用ReLU6的优化实现。其次,它能在特定模式下消除了由于近似sigmoid的不同实现而带来的潜在数值精度损失。图1即为sigmoid和wish以及对应的hard版本,hard形式其实就是soft形式的低精度化。
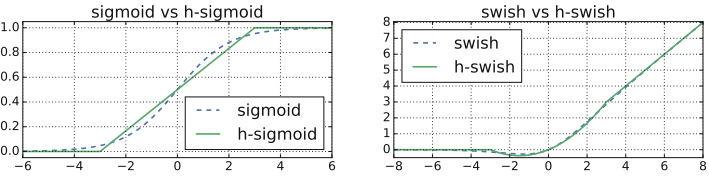
图1(源自Ref [1])
需要注意的是,MobileNet是来自于Google的,自然它更关注的是网络在Android设备上的表现,事实也的确如此,作者主要针对Google Pixel硬件对网络做了参数优化。
当然这并不意味着MobileNet V3就是慢的了,只不过它无法在iOS上达到最佳效果。
不过,并非整个模型都使用了h-swish,模型的前一半层使用常规ReLU(第一个conv层之后的除外)。 为什么要这样做呢?
因为作者发现,h-swish仅在更深层次上有用。 此外,考虑到特征图在较浅的层中往往更大,因此计算其激活成本更高,所以作者选择在这些层上简单地使用ReLU(而非ReLU6),因为它比h-swish省时。
对于第6点,具体解释一下如何完成ReLU6(x + 3) / 6的。如图2所示,在Mul层中,做了乘以0.16667的乘法,这就相当于除以6;ReLU6则融合在了卷积层之中;另外,对于x+3,这里的3被加在了卷积层的偏置层中了。这样做也是一种小的优化方式。
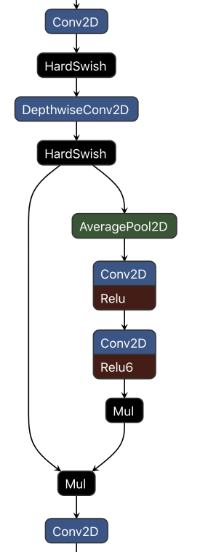
图2(源自Ref [2])
除了以上提到的,相对于V2,在V3中作者还对最后的层进行了优化。
在MobileNetV2中,在全局平均池化层之前,是一个1 × 1卷积,将通道数从320扩展到1280,因此我们就能得到更高维度的特征,供分类器层使用。 这样做的好处是,在预测时有更多更丰富的特征来满足预测,但是同时也引入了额外的计算成本与延时。
所以,需要改进的地方就是要保留高维特征的前提下减小延时。
在MobileNetV3中,这个1 x 1卷积层位于全局平均池化层的后面,因此它可用于更小的特征图,因此速度更快。如图3所示, 这样使我们就能够删除前面的bottleneck层和depthwise convolution层,而不会降低准确性。
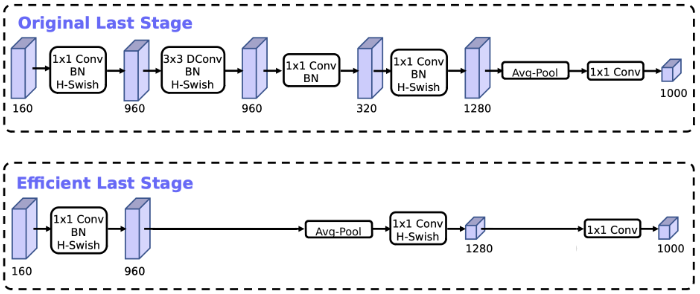
图3(源自Ref [2])
可以看到,现在最后两个卷积后面都没有BN层了。
由于这些改进,虽然MobileNetV3使用了与MnasNet相同类型的构造块,而且具有更多参数,MobileNet v3仍比MnasNet更快,并且具有相同的精度。
二、V3的几种变体以及它们的效果
MobileNet v3仍然使用宽度乘子的概念。 因此,有很多方法可以调整模型的大小和形状。 与之前的版本一样,该架构不仅定义了单个模型,还定义了一系列的变体:
- Large:就如前所述的
- Small:包含了更少的构造块和更少的滤波器
- Large minimalistic:和Large类似,但是没有SE、h-swish和5 x 5卷积
- Small minimalistic:和Small的变体类似
2.1 ImageNet的分类准确率
| Model | Params | top-1 | top-5 |
|---|---|---|---|
| MobileNetV3 (small) | 2.9 M | 67.5% | 87.7% |
| MobileNetV3 (large) | 5.4 M | 75.2% | 92.2% |
MobileNetV3-large的准确率几乎与ResNet-50相同了;与MnasNet-A3相比,它的准确率稍低,两者的参数量相当; 它与具有1.4宽度乘子的v2相比,两者的top-1精度也达到75%,前者的参数量为5.4M,而后者达到了6M。
MobileNetV3-small可以和宽度乘子为0.75的V2相比,前者的参数量为2.9M,后者的参数量为2.6M,不过后者的top-1准确达到了69.8%,比前者的67.5%更高。
2.2 语义分割的效果
作者将V2中的分割头称为R-ASPP(Reduced Atrous Spatial Pyramid Pooling),包含了一个1 x 1卷积层和一个全局平均池化层。在V3中,作者又另外提出了LR-ASPP,使用了一个大型卷积核、大步长的全局平均池化层和一个1 x 1卷积。 作者在V3的最后一个块后加上空洞卷积,来提取密集特征,然后添加了一个低层级的特征,来捕获细节信息,如图4所示。
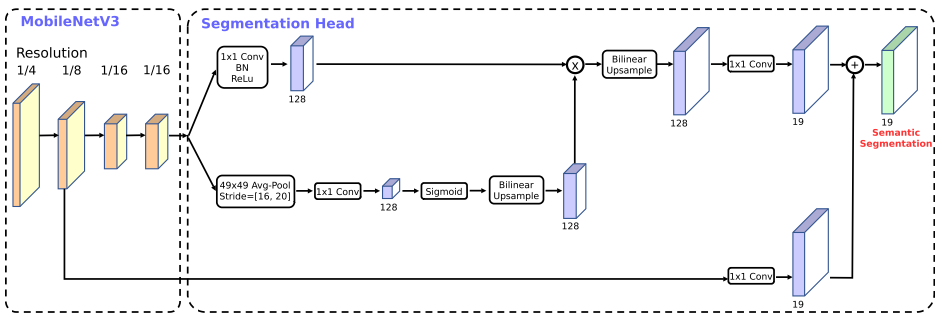
图4(源自Ref [1])
两者在Cityscapes验证集上的比较结果如下图5所示。RF2指的是在最后一个块中,将通道数减半;SH指的是分割头;×指的是使用R-ASPP,√指的是使用LR-ASPP;F指的是分割头中使用的滤波器数量;CPU(f)指的是全分辨率输入(即1024×2048)时测量的CPU时间; CPU(h)指的是半分辨率输入(即512×1024)时测量的CPU时间。
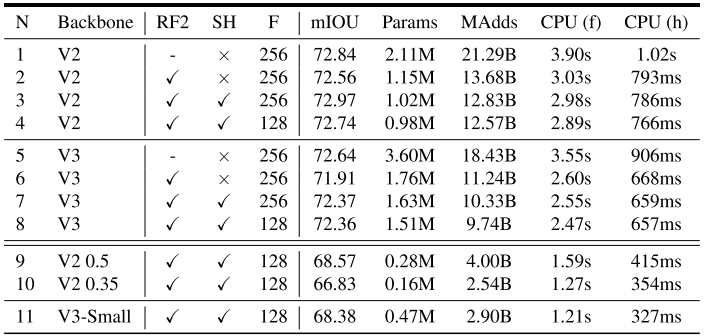
图5(源自Ref [1])
(1)将网络主干的最后一个块中的通道减少2倍,可以显着提高速度,同时保持相似的性能[N1 vs N2, N5 vs N6];
(2)LR-ASPP比R-ASPP的速度更快,同时性能有所改善[N2 vs N3, N6 vs N7];
(3)将分割头中的滤波器从256减少到128会提高速度,但性能会稍差[N3 vs N4, N7 vs N8];
(4)在相同配置下,V3变体与V2的表现相似,速度比V2稍快[N1 vs N3, N2 vs N6, N3 vs N7, N4 vs N8];
(5)V3-Small的表现与V2-0.5类似,但是速度更快;
(6)V3-Small和V2-0.35的速度类似,但表现更好。
使用V3和V3-small在Cityscapes测试集上的结果显示,若在模型的最后一个块中,不使用空洞卷积来提取密集特征,效果会下降0.6%,但速度会有所提升。
Reference
[1]. Searching for MobileNetV3