一、介绍
VGG-nets、ResNet和Inception Networks在特征提取领域已经取得了极大的成就,但他们仍然面对一系列的难题。例如,这些模型可能适用于某些数据集,但是由于它们使用了太多的超参数和计算过程,我们就很难将其直接移植到新的数据集上。
为了克服这些问题,业界已经考虑了结合VGG/ResNet(ResNet是从VGG演变而来的)和Inception Networks的优势。 简而言之,就是将ResNet的重复策略(repetition strategy)与Inception Network的拆分-转换-合并策略(split-transform-merge strategy)相结合。 换句话说,网络模块将输入分割,将其转换为所需的格式,然后合并以获取输出,每个模块都遵循相同的拓扑(如图1右侧)。
ResNeXt出现于Aggregated Residual Transformations for Deep Neural Networks,它是一种具有均一性的神经网络,相对于传统的ResNet,ResNeXt减小了超参数的数量。ResNeXt,其中包含了Next,这就意味一个额外的维度。作者在宽度(width)和深度(depth)以外,还提出了一个称为cardinality的参数。
图1左侧是传统的ResNet block;右侧是ResNeXt block,其cardinality是32,可以看出该参数其实就是内部路径数。
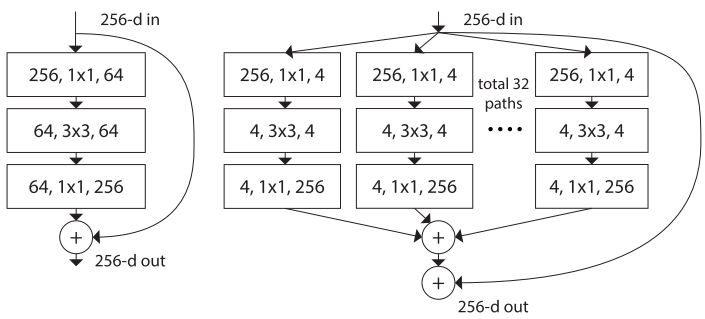
图1
-
ResNeXt block遵循 split-transform-aggregate策略。
-
ResNeXt block内部路径的数量就是
cardinality,在图1中C=32。 -
ResNeXt block的所有路径具有相同的拓扑结构。
-
作者没有使用深度和宽度,而是采用了cardinality,较高的数值能够减小验证误差。
-
和ResNet相比,ResNeXt block使用了更多的子空间(也就是C>1)。
-
两个架构具有不同的宽度(即通道数)。ResNet的Layer-1的1个卷积层通道数为64,ResNeXt的Layer-1有32个不同卷积层,通道数均为4(一共是32$\times$4个通道数)。虽然ResNeXt block的通道数更多,但两个架构的参数量是一样的(约70k)。
ResNet:
$256\times64+3\times3\times64\times64+64\times26$ResNeXt:
$C\times(256 \times d+3\times3 \times d \times d+d \times 256$, with$ C=32$ and $d=4$
二、合并转换策略
2.1 回顾一下简单的神经元
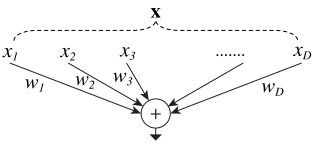
图2
如图2所示,一个简单神经元的输出是$w{i} x{i}$的总和。上述的操作就可以定义为 splitting, transforming和aggregating。
(1)拆分:向量$x$被拆分成低维的子空间。在图2中,它指的就是一维的子空间$x_i$。
(2)转换:低维的表征将会被转换。在图2中,它们被简单地缩放了,即$w{i} x{i}$。
(3)合并:将所有转换后的结果相加。
2.2 合并转换
如图3所示,作者提出了Network-in-Neuron的概念,拓展了一个新维度。也就是说,在原先每条$w{i} x{i}$的路径上,现在采用的是一个非线性变化函数。
这个新维度就是Cardinality,简称C。如前所述,该维度控制的是transformatiom过程中非线性变化函数的数量。
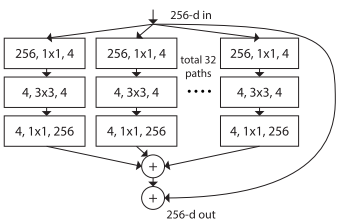
图3
三、架构
ResNeXt的基本架构主要遵循两个规则:
(1)如果blocks产生相同维度的空间图,那么它们共享同一组超参数;
(2)如果空间图完全以缩放因子2进行下采样,则blocks的宽度(通道数)乘以2。
如图4所示,ResNeXt-50的conv2、conv3、conv4和conv5的cardinality均为32,深度(depth)分别为3、4、6和3。C=32指的是在每个ResNeXt block中有32条路径。 注意到ResNeXt-50的参数量少于ResNet-50。
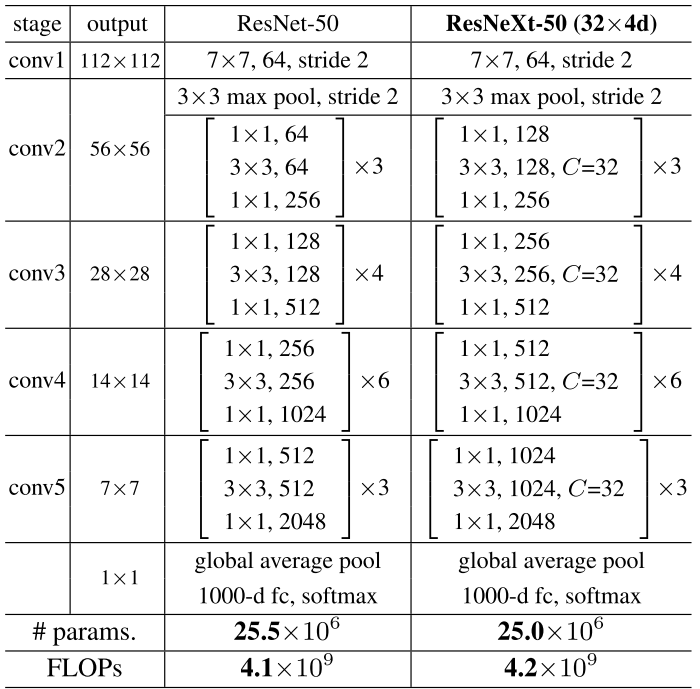
图4
如图5所示,(a)(b)(c)的block实现效果是相同的。
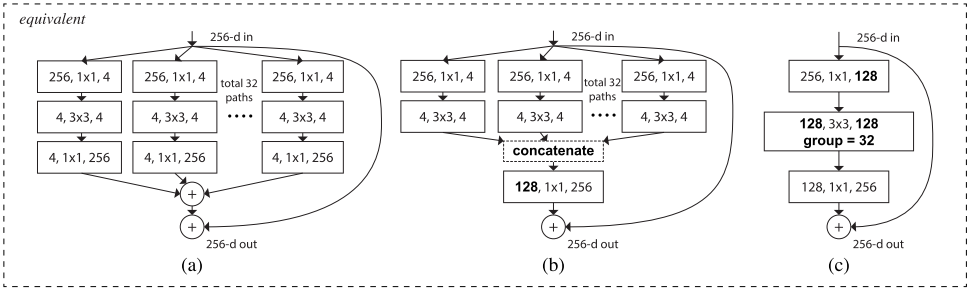
图5
(a)ResNeXt Block
-
在每条卷积路径中,均有Conv1×1–Conv3×3–Conv1×1,这个其实就是ResNet block中的bottleneck。每条路径中的内部通道数可以定义为
$d$($d=4$),路径的数量称为cardinality$C$($C=32$)。如果我们把每个Conv3×3(比如d×C=4×32)的通道数相加,也就是128。 -
接下来,将通道数从4增加到256,然后把所有路径的输出相加,再加上跳连接的路径。
-
与Inception-ResNet相比,ResNeXt仅需最低的成本就可以为每条路径设计卷积层(通道数从4到128到256)。
-
与ResNet不同的是,ResNeXt中的每条路径不会与其他路径上的神经元相连。
(b)Inception-ResNet Block
-
在Inception-v4中,作者将Inception模块和ResNet Block组合。由于历史遗留问题,对于每个卷积路径,作者先完成了Conv1×1–Conv3×3。将它们的通道数相加以后(4×32),Conv3×3 的通道数就是128了。
-
使用Conv1×1将通道数从128恢复为256。
-
最后,将结果加上跳连接。
(c)Grouped Convolution in AlexNet
-
在每个卷积路径中,均有Conv1×1–Conv3×3–Conv1×1,这个其实就是ResNet block中的bottleneck。Conv3×3的通道为128。
-
在这里使用了群卷积,因此这个Conv3×3模块更宽,但是稀疏连接的(因为每条路径中的神经元不会与其他路径上的神经元相连,那就是稀疏连接的原因)。
-
因此,在这里就有32个群卷积(AlexNet中只有2个)。
-
最后将跳连接加到结果上。
在以上3个中,(c)是最好的,因为它易于实现。
三、训练结果
3.1 Cardinality vs width
当考虑cardinality而不是宽度/深度时,如图6所示,当C从1增加到32时,我们可以看到top-1 % error rate逐渐下降。因此,增加C的同时减小通道数,能够提高模型的效果。
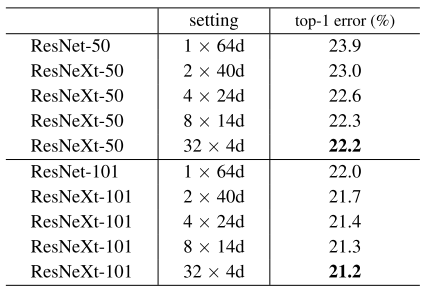
图6
3.2 Increasing Cardinality vs Deeper/Wider
在这里主要列举了3中情况:
(1)将层数从101增加到200(deeper)
(2)增加bottleneck的通道数(wider)
(3)将cardinality加倍
所得结果如图7所示,增加C能够获得更好的结果。
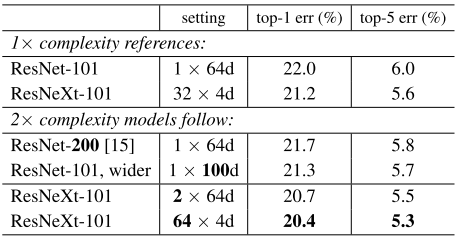
图7
此外,与ResNet相比,ResNeXt表现更良好。
四、代码实现
五、Reference
[1]. Aggregated Residual Transformations for Deep Neural Networks
[2]. A Review of Popular Deep Learning Architectures: DenseNet, ResNeXt, MnasNet, and ShuffleNet v2
[3]. ResNeXt Block
[4]. Review: ResNeXt — 1st Runner Up in ILSVRC 2016 (Image Classification)